Information that has been collected through research. Research data management, metadata, data repositories, data citations, data sharing, data reuse, and more.
Software Carpentry lesson that teaches how to use databases and SQL In …
Software Carpentry lesson that teaches how to use databases and SQL In the late 1920s and early 1930s, William Dyer, Frank Pabodie, and Valentina Roerich led expeditions to the Pole of Inaccessibility in the South Pacific, and then onward to Antarctica. Two years ago, their expeditions were found in a storage locker at Miskatonic University. We have scanned and OCR the data they contain, and we now want to store that information in a way that will make search and analysis easy. Three common options for storage are text files, spreadsheets, and databases. Text files are easiest to create, and work well with version control, but then we would have to build search and analysis tools ourselves. Spreadsheets are good for doing simple analyses, but they don’t handle large or complex data sets well. Databases, however, include powerful tools for search and analysis, and can handle large, complex data sets. These lessons will show how to use a database to explore the expeditions’ data.
By encouraging and requiring that authors share their data in order to …
By encouraging and requiring that authors share their data in order to publish articles, scholarly journals have become an important actor in the movement to improve the openness of data and the reproducibility of research. But how many social science journals encourage or mandate that authors share the data supporting their research findings? How does the share of journal data policies vary by discipline? What influences these journals’ decisions to adopt such policies and instructions? And what do those policies and instructions look like? We discuss the results of our analysis of the instructions and policies of 291 highly-ranked journals publishing social science research, where we studied the contents of journal data policies and instructions across 14 variables, such as when and how authors are asked to share their data, and what role journal ranking and age play in the existence and quality of data policies and instructions. We also compare our results to the results of other studies that have analyzed the policies of social science journals, although differences in the journals chosen and how each study defines what constitutes a data policy limit this comparison.We conclude that a little more than half of the journals in our study have data policies. A greater share of the economics journals have data policies and mandate sharing, followed by political science/international relations and psychology journals. Finally, we use our findings to make several recommendations: Policies should include the terms “data,� “dataset� or more specific terms that make it clear what to make available; policies should include the benefits of data sharing; journals, publishers, and associations need to collaborate more to clarify data policies; and policies should explicitly ask for qualitative data.
Background. Attribution to the original contributor upon reuse of published data is …
Background. Attribution to the original contributor upon reuse of published data is important both as a reward for data creators and to document the provenance of research findings. Previous studies have found that papers with publicly available datasets receive a higher number of citations than similar studies without available data. However, few previous analyses have had the statistical power to control for the many variables known to predict citation rate, which has led to uncertain estimates of the “citation benefit”. Furthermore, little is known about patterns in data reuse over time and across datasets. Method and Results. Here, we look at citation rates while controlling for many known citation predictors and investigate the variability of data reuse. In a multivariate regression on 10,555 studies that created gene expression microarray data, we found that studies that made data available in a public repository received 9% (95% confidence interval: 5% to 13%) more citations than similar studies for which the data was not made available. Date of publication, journal impact factor, open access status, number of authors, first and last author publication history, corresponding author country, institution citation history, and study topic were included as covariates. The citation benefit varied with date of dataset deposition: a citation benefit was most clear for papers published in 2004 and 2005, at about 30%. Authors published most papers using their own datasets within two years of their first publication on the dataset, whereas data reuse papers published by third-party investigators continued to accumulate for at least six years. To study patterns of data reuse directly, we compiled 9,724 instances of third party data reuse via mention of GEO or ArrayExpress accession numbers in the full text of papers. The level of third-party data use was high: for 100 datasets deposited in year 0, we estimated that 40 papers in PubMed reused a dataset by year 2, 100 by year 4, and more than 150 data reuse papers had been published by year 5. Data reuse was distributed across a broad base of datasets: a very conservative estimate found that 20% of the datasets deposited between 2003 and 2007 had been reused at least once by third parties. Conclusion. After accounting for other factors affecting citation rate, we find a robust citation benefit from open data, although a smaller one than previously reported. We conclude there is a direct effect of third-party data reuse that persists for years beyond the time when researchers have published most of the papers reusing their own data. Other factors that may also contribute to the citation benefit are considered. We further conclude that, at least for gene expression microarray data, a substantial fraction of archived datasets are reused, and that the intensity of dataset reuse has been steadily increasing since 2003.
A number of publishers and funders, including PLOS, have recently adopted policies …
A number of publishers and funders, including PLOS, have recently adopted policies requiring researchers to share the data underlying their results and publications. Such policies help increase the reproducibility of the published literature, as well as make a larger body of data available for reuse and re-analysis. In this study, we evaluate the extent to which authors have complied with this policy by analyzing Data Availability Statements from 47,593 papers published in PLOS ONE between March 2014 (when the policy went into effect) and May 2016. Our analysis shows that compliance with the policy has increased, with a significant decline over time in papers that did not include a Data Availability Statement. However, only about 20% of statements indicate that data are deposited in a repository, which the PLOS policy states is the preferred method. More commonly, authors state that their data are in the paper itself or in the supplemental information, though it is unclear whether these data meet the level of sharing required in the PLOS policy. These findings suggest that additional review of Data Availability Statements or more stringent policies may be needed to increase data sharing.
Sharing data and code are important components of reproducible research. Data sharing …
Sharing data and code are important components of reproducible research. Data sharing in research is widely discussed in the literature; however, there are no well-established evidence-based incentives that reward data sharing, nor randomized studies that demonstrate the effectiveness of data sharing policies at increasing data sharing. A simple incentive, such as an Open Data Badge, might provide the change needed to increase data sharing in health and medical research. This study was a parallel group randomized controlled trial (protocol registration: doi:10.17605/OSF.IO/PXWZQ) with two groups, control and intervention, with 80 research articles published in BMJ Open per group, with a total of 160 research articles. The intervention group received an email offer for an Open Data Badge if they shared their data along with their final publication and the control group received an email with no offer of a badge if they shared their data with their final publication. The primary outcome was the data sharing rate. Badges did not noticeably motivate researchers who published in BMJ Open to share their data; the odds of awarding badges were nearly equal in the intervention and control groups (odds ratio = 0.9, 95% CI [0.1, 9.0]). Data sharing rates were low in both groups, with just two datasets shared in each of the intervention and control groups. The global movement towards open science has made significant gains with the development of numerous data sharing policies and tools. What remains to be established is an effective incentive that motivates researchers to take up such tools to share their data.
Objectives To identify and appraise empirical studies on publication and related biases …
Objectives To identify and appraise empirical studies on publication and related biases published since 1998; to assess methods to deal with publication and related biases; and to examine, in a random sample of published systematic reviews, measures taken to prevent, reduce and detect dissemination bias. Data sources The main literature search, in August 2008, covered the Cochrane Methodology Register Database, MEDLINE, EMBASE, AMED and CINAHL. In May 2009, PubMed, PsycINFO and OpenSIGLE were also searched. Reference lists of retrieved studies were also examined. Review methods In Part I, studies were classified as evidence or method studies and data were extracted according to types of dissemination bias or methods for dealing with it. Evidence from empirical studies was summarised narratively. In Part II, 300 systematic reviews were randomly selected from MEDLINE and the methods used to deal with publication and related biases were assessed. Results Studies with significant or positive results were more likely to be published than those with non-significant or negative results, thereby confirming findings from a previous HTA report. There was convincing evidence that outcome reporting bias exists and has an impact on the pooled summary in systematic reviews. Studies with significant results tended to be published earlier than studies with non-significant results, and empirical evidence suggests that published studies tended to report a greater treatment effect than those from the grey literature. Exclusion of non-English-language studies appeared to result in a high risk of bias in some areas of research such as complementary and alternative medicine. In a few cases, publication and related biases had a potentially detrimental impact on patients or resource use. Publication bias can be prevented before a literature review (e.g. by prospective registration of trials), or detected during a literature review (e.g. by locating unpublished studies, funnel plot and related tests, sensitivity analysis modelling), or its impact can be minimised after a literature review (e.g. by confirmatory large-scale trials, updating the systematic review). The interpretation of funnel plot and related statistical tests, often used to assess publication bias, was often too simplistic and likely misleading. More sophisticated modelling methods have not been widely used. Compared with systematic reviews published in 1996, recent reviews of health-care interventions were more likely to locate and include non-English-language studies and grey literature or unpublished studies, and to test for publication bias. Conclusions Dissemination of research findings is likely to be a biased process, although the actual impact of such bias depends on specific circumstances. The prospective registration of clinical trials and the endorsement of reporting guidelines may reduce research dissemination bias in clinical research. In systematic reviews, measures can be taken to minimise the impact of dissemination bias by systematically searching for and including relevant studies that are difficult to access. Statistical methods can be useful for sensitivity analyses. Further research is needed to develop methods for qualitatively assessing the risk of publication bias in systematic reviews, and to evaluate the effect of prospective registration of studies, open access policy and improved publication guidelines.
A Data Carpentry curriculum for Economics is being developed by Dr. Miklos …
A Data Carpentry curriculum for Economics is being developed by Dr. Miklos Koren at Central European University. These materials are being piloted locally. Development for these lessons has been supported by a grant from the Sloan Foundation.
Software Carpentry lección para control de versiones con Git Para ilustrar el …
Software Carpentry lección para control de versiones con Git Para ilustrar el poder de Git y GitHub, usaremos la siguiente historia como un ejemplo motivador a través de esta lección. El Hombre Lobo y Drácula han sido contratados por Universal Missions para investigar si es posible enviar su próximo explorador planetario a Marte. Ellos quieren poder trabajar al mismo tiempo en los planes, pero ya han experimentado ciertos problemas anteriormente al hacer algo similar. Si se rotan por turnos entonces cada uno gastará mucho tiempo esperando a que el otro termine, pero si trabajan en sus propias copias e intercambian los cambios por email, las cosas se perderán, se sobreescribirán o se duplicarán. Un colega sugiere utilizar control de versiones para lidiar con el trabajo. El control de versiones es mejor que el intercambio de ficheros por email: Nada se pierde una vez que se incluye bajo control de versiones, a no ser que se haga un esfuerzo sustancial. Como se van guardando todas las versiones precedentes de los ficheros, siempre es posible volver atrás en el tiempo y ver exactamente quién escribió qué en un día en particular, o qué versión de un programa fue utilizada para generar un conjunto de resultados en particular. Como se tienen estos registros de quién hizo qué y en qué momento, es posible saber a quién preguntar si se tiene una pregunta en un momento posterior y, si es necesario, revertir el contenido a una versión anterior, de forma similar a como funciona el comando “deshacer” de los editores de texto. Cuando varias personas colaboran en el mismo proyecto, es posible pasar por alto o sobreescribir de manera accidental los cambios hechos por otra persona. El sistema de control de versiones notifica automáticamente a los usuarios cada vez que hay un conflicto entre el trabajo de una persona y la otra. Los equipos no son los únicos que se benefician del control de versiones: los investigadores independientes se pueden beneficiar en gran medida. Mantener un registro de qué ha cambiado, cuándo y por qué es extremadamente útil para todos los investigadores si alguna vez necesitan retomar el proyecto en un momento posterior (e.g. un año después, cuando se ha desvanecido el recuerdo de los detalles).
Background Many journals now require authors share their data with other investigators, …
Background Many journals now require authors share their data with other investigators, either by depositing the data in a public repository or making it freely available upon request. These policies are explicit, but remain largely untested. We sought to determine how well authors comply with such policies by requesting data from authors who had published in one of two journals with clear data sharing policies. Methods and Findings We requested data from ten investigators who had published in either PLoS Medicine or PLoS Clinical Trials. All responses were carefully documented. In the event that we were refused data, we reminded authors of the journal's data sharing guidelines. If we did not receive a response to our initial request, a second request was made. Following the ten requests for raw data, three investigators did not respond, four authors responded and refused to share their data, two email addresses were no longer valid, and one author requested further details. A reminder of PLoS's explicit requirement that authors share data did not change the reply from the four authors who initially refused. Only one author sent an original data set. Conclusions We received only one of ten raw data sets requested. This suggests that journal policies requiring data sharing do not lead to authors making their data sets available to independent investigators.
We have empirically assessed the distribution of published effect sizes and estimated …
We have empirically assessed the distribution of published effect sizes and estimated power by analyzing 26,841 statistical records from 3,801 cognitive neuroscience and psychology papers published recently. The reported median effect size was D = 0.93 (interquartile range: 0.64–1.46) for nominally statistically significant results and D = 0.24 (0.11–0.42) for nonsignificant results. Median power to detect small, medium, and large effects was 0.12, 0.44, and 0.73, reflecting no improvement through the past half-century. This is so because sample sizes have remained small. Assuming similar true effect sizes in both disciplines, power was lower in cognitive neuroscience than in psychology. Journal impact factors negatively correlated with power. Assuming a realistic range of prior probabilities for null hypotheses, false report probability is likely to exceed 50% for the whole literature. In light of our findings, the recently reported low replication success in psychology is realistic, and worse performance may be expected for cognitive neuroscience.
Psychological science is navigating an unprecedented period of introspection about the credibility …
Psychological science is navigating an unprecedented period of introspection about the credibility and utility of its research. A number of reform initiatives aimed at increasing adoption of transparency and reproducibility-related research practices appear to have been effective in specific contexts; however, their broader, collective impact amidst a wider discussion about research credibility and reproducibility is largely unknown. In the present study, we estimated the prevalence of several transparency and reproducibility-related indicators in the psychology literature published between 2014-2017 by manually assessing these indicators in a random sample of 250 articles. Over half of the articles we examined were publicly available (154/237, 65% [95% confidence interval, 59% to 71%]). However, sharing of important research resources such as materials (26/183, 14% [10% to 19%]), study protocols (0/188, 0% [0% to 1%]), raw data (4/188, 2% [1% to 4%]), and analysis scripts (1/188, 1% [0% to 1%]) was rare. Pre-registration was also uncommon (5/188, 3% [1% to 5%]). Although many articles included a funding disclosure statement (142/228, 62% [56% to 69%]), conflict of interest disclosure statements were less common (88/228, 39% [32% to 45%]). Replication studies were rare (10/188, 5% [3% to 8%]) and few studies were included in systematic reviews (21/183, 11% [8% to 16%]) or meta-analyses (12/183, 7% [4% to 10%]). Overall, the findings suggest that transparent and reproducibility-related research practices are far from routine in psychological science. Future studies can use the present findings as a baseline to assess progress towards increasing the credibility and utility of psychology research.
A focus on novel, confirmatory, and statistically significant results leads to substantial …
A focus on novel, confirmatory, and statistically significant results leads to substantial bias in the scientific literature. One type of bias, known as “p-hacking,” occurs when researchers collect or select data or statistical analyses until nonsignificant results become significant. Here, we use text-mining to demonstrate that p-hacking is widespread throughout science. We then illustrate how one can test for p-hacking when performing a meta-analysis and show that, while p-hacking is probably common, its effect seems to be weak relative to the real effect sizes being measured. This result suggests that p-hacking probably does not drastically alter scientific consensuses drawn from meta-analyses.
In this article, we accomplish two things. First, we show that despite …
In this article, we accomplish two things. First, we show that despite empirical psychologists’ nominal endorsement of a low rate of false-positive findings (≤ .05), flexibility in data collection, analysis, and reporting dramatically increases actual false-positive rates. In many cases, a researcher is more likely to falsely find evidence that an effect exists than to correctly find evidence that it does not. We present computer simulations and a pair of actual experiments that demonstrate how unacceptably easy it is to accumulate (and report) statistically significant evidence for a false hypothesis. Second, we suggest a simple, low-cost, and straightforwardly effective disclosure-based solution to this problem. The solution involves six concrete requirements for authors and four guidelines for reviewers, all of which impose a minimal burden on the publication process.
The FOSTER portal is an e-learning platform that brings together the best …
The FOSTER portal is an e-learning platform that brings together the best training resources addressed to those who need to know more about Open Science, or need to develop strategies and skills for implementing Open Science practices in their daily workflows. Here you will find a growing collection of training materials. Many different users - from early-career researchers, to data managers, librarians, research administrators, and graduate schools - can benefit from the portal. In order to meet their needs, the existing materials will be extended from basic to more advanced-level resources. In addition, discipline-specific resources will be created.
This report covers funder data-sharing policies/practices, and provides recommendations to funders and …
This report covers funder data-sharing policies/practices, and provides recommendations to funders and others as they consider their own policies. It was commissioned by Robert Wood Johnson Foundation in 2017. If any comments or questions, please contact Stephanie Wykstra (stephanie.wykstra@gmail.com).
Workshop overview for the Data Carpentry genomics curriculum. Data Carpentry’s aim is …
Workshop overview for the Data Carpentry genomics curriculum. Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools for working with data so that they can get more done in less time, and with less pain. This workshop teaches data management and analysis for genomics research including: best practices for organization of bioinformatics projects and data, use of command-line utilities, use of command-line tools to analyze sequence quality and perform variant calling, and connecting to and using cloud computing. This workshop is designed to be taught over two full days of instruction. Please note that workshop materials for working with Genomics data in R are in “alpha” development. These lessons are available for review and for informal teaching experiences, but are not yet part of The Carpentries’ official lesson offerings. Interested in teaching these materials? We have an onboarding video and accompanying slides available to prepare Instructors to teach these lessons. After watching this video, please contact team@carpentries.org so that we can record your status as an onboarded Instructor. Instructors who have completed onboarding will be given priority status for teaching at centrally-organized Data Carpentry Genomics workshops.
Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools …
Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools for working with data so that they can get more done in less time, and with less pain. Interested in teaching these materials? We have an onboarding video available to prepare Instructors to teach these lessons. After watching this video, please contact team@carpentries.org so that we can record your status as an onboarded Instructor. Instructors who have completed onboarding will be given priority status for teaching at centrally-organized Data Carpentry Geospatial workshops.
This webinar outlines how to use the free Open Science Framework (OSF) …
This webinar outlines how to use the free Open Science Framework (OSF) as an Electronic Lab Notebook for personal work or private collaborations. Fundamental features we cover include how to record daily activity, how to store images or arbitrary data files, how to invite collaborators, how to view old versions of files, and how to connect all this usage to more complex structures that support the full work of a lab across multiple projects and experiments.
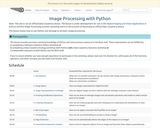
This lesson shows how to use Python and skimage to do basic …
This lesson shows how to use Python and skimage to do basic image processing. With support from an NSF iUSE grant, Dr. Tessa Durham Brooks and Dr. Mark Meysenburg at Doane College, Nebraska, USA have developed a curriculum for teaching image processing in Python. This lesson is currently being piloted at different institutions. This pilot phase will be followed by a clean-up phase to incorporate suggestions and feedback from the pilots into the lessons and to make the lessons teachable by the broader community. Development for these lessons has been supported by a grant from the Sloan Foundation.
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.