Short Description: Database Design - 2nd Edition covers database systems and database …
Short Description: Database Design - 2nd Edition covers database systems and database design concepts. New to this edition are SQL info, additional examples, key terms and review exercises at the end of each chapter.
Long Description: This second edition of Database Design book covers the concepts used in database systems and the database design process. Topics include: The history of databases Characteristics and benefits of databases Data models Data modelling Classification of database management systems Integrity rules and constraints Functional dependencies Normalization Database development process
Word Count: 30650
(Note: This resource's metadata has been created automatically by reformatting and/or combining the information that the author initially provided as part of a bulk import process.)
Software Carpentry lesson that teaches how to use databases and SQL In …
Software Carpentry lesson that teaches how to use databases and SQL In the late 1920s and early 1930s, William Dyer, Frank Pabodie, and Valentina Roerich led expeditions to the Pole of Inaccessibility in the South Pacific, and then onward to Antarctica. Two years ago, their expeditions were found in a storage locker at Miskatonic University. We have scanned and OCR the data they contain, and we now want to store that information in a way that will make search and analysis easy. Three common options for storage are text files, spreadsheets, and databases. Text files are easiest to create, and work well with version control, but then we would have to build search and analysis tools ourselves. Spreadsheets are good for doing simple analyses, but they don’t handle large or complex data sets well. Databases, however, include powerful tools for search and analysis, and can handle large, complex data sets. These lessons will show how to use a database to explore the expeditions’ data.
The home of the U.S. Government’s open data. Here you will find …
The home of the U.S. Government’s open data. Here you will find data, tools, and resources to conduct research, develop web and mobile applications, design data visualizations, and more. Topics include Agriculture, Business, Climate, Education, Energy, Ecosystems, Manufacturing and more.
Those workshops help to gain new skills in research data management. Created …
Those workshops help to gain new skills in research data management. Created by MIT Libraries, under CC-BY license, others can adapt and utilize this resources to develop thier own slides in teaching data management.
Background. Attribution to the original contributor upon reuse of published data is …
Background. Attribution to the original contributor upon reuse of published data is important both as a reward for data creators and to document the provenance of research findings. Previous studies have found that papers with publicly available datasets receive a higher number of citations than similar studies without available data. However, few previous analyses have had the statistical power to control for the many variables known to predict citation rate, which has led to uncertain estimates of the “citation benefit”. Furthermore, little is known about patterns in data reuse over time and across datasets. Method and Results. Here, we look at citation rates while controlling for many known citation predictors and investigate the variability of data reuse. In a multivariate regression on 10,555 studies that created gene expression microarray data, we found that studies that made data available in a public repository received 9% (95% confidence interval: 5% to 13%) more citations than similar studies for which the data was not made available. Date of publication, journal impact factor, open access status, number of authors, first and last author publication history, corresponding author country, institution citation history, and study topic were included as covariates. The citation benefit varied with date of dataset deposition: a citation benefit was most clear for papers published in 2004 and 2005, at about 30%. Authors published most papers using their own datasets within two years of their first publication on the dataset, whereas data reuse papers published by third-party investigators continued to accumulate for at least six years. To study patterns of data reuse directly, we compiled 9,724 instances of third party data reuse via mention of GEO or ArrayExpress accession numbers in the full text of papers. The level of third-party data use was high: for 100 datasets deposited in year 0, we estimated that 40 papers in PubMed reused a dataset by year 2, 100 by year 4, and more than 150 data reuse papers had been published by year 5. Data reuse was distributed across a broad base of datasets: a very conservative estimate found that 20% of the datasets deposited between 2003 and 2007 had been reused at least once by third parties. Conclusion. After accounting for other factors affecting citation rate, we find a robust citation benefit from open data, although a smaller one than previously reported. We conclude there is a direct effect of third-party data reuse that persists for years beyond the time when researchers have published most of the papers reusing their own data. Other factors that may also contribute to the citation benefit are considered. We further conclude that, at least for gene expression microarray data, a substantial fraction of archived datasets are reused, and that the intensity of dataset reuse has been steadily increasing since 2003.
A number of publishers and funders, including PLOS, have recently adopted policies …
A number of publishers and funders, including PLOS, have recently adopted policies requiring researchers to share the data underlying their results and publications. Such policies help increase the reproducibility of the published literature, as well as make a larger body of data available for reuse and re-analysis. In this study, we evaluate the extent to which authors have complied with this policy by analyzing Data Availability Statements from 47,593 papers published in PLOS ONE between March 2014 (when the policy went into effect) and May 2016. Our analysis shows that compliance with the policy has increased, with a significant decline over time in papers that did not include a Data Availability Statement. However, only about 20% of statements indicate that data are deposited in a repository, which the PLOS policy states is the preferred method. More commonly, authors state that their data are in the paper itself or in the supplemental information, though it is unclear whether these data meet the level of sharing required in the PLOS policy. These findings suggest that additional review of Data Availability Statements or more stringent policies may be needed to increase data sharing.
In this lab, students are introduced to the difference between relative and …
In this lab, students are introduced to the difference between relative and absolute dating, using the students themselves as the material to be ordered. Initially, the students are asked to develop physical clues to put themselves in order from youngest to oldest (exposing the inferences we make unconsciously about people's ages), and this will be refined/modified using a list of current events from an appropriate historical period that more and more of the students will remember, depending on their age (among other variables). Absolute age is introduced by having the students order themselves by birth decade, year, month, and day, and comparing the absolute age order to the order worked out in the relative-dating exercise, with a discussion of dating precision and accuracy.
(Note: this resource was added to OER Commons as part of a batch upload of over 2,200 records. If you notice an issue with the quality of the metadata, please let us know by using the 'report' button and we will flag it for consideration.)
Michael Ridley, Librarian Emeritus, University of Guelph delivers the Keynote for day …
Michael Ridley, Librarian Emeritus, University of Guelph delivers the Keynote for day two of the Fantastic Futures ai4LAM 2023 annual conference. This item belongs to: movies/fantastic-futures-annual-international-conference-2023-ai-for-libraries-archives-and-museums-02.
This item has files of the following types: Archive BitTorrent, Item Tile, MP3, MPEG4, Metadata, PNG, Thumbnail, h.264 720P, h.264 IA
We prepared teachers to hold a deliberative democratic student climate assembly by …
We prepared teachers to hold a deliberative democratic student climate assembly by teaching about learning standards, climate science and local resources, teaching tools and resources, deliberative democracies and student conversations, climate anxiety and climate justice and the Inquiry Design Model. Guest speakers Lori Henrickson, OSPI project manager for this project, spoke at the summer and spring workshop along with pilot SCA teacher at Glacier Peak HS Ryan Hauck.Resources include: the powerpoint slides from the workshop & a word document with the resources provided.
Density columns are a great way to introduce kids to mass, volume, …
Density columns are a great way to introduce kids to mass, volume, and density! With hands-on activities, kids can see how liquids float or sink based on their density. They can also experiment with objects around them by adding them to the density column and watching them float or sink.
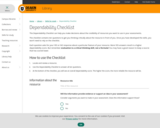
The Dependability Checklist is a tool to help students evaluate resources for …
The Dependability Checklist is a tool to help students evaluate resources for their assessments. Students answer ten 'yes' or 'no' questions about a resource and then generate a score indicating how trustworthy or dependable that resource is. Working through the Checklist introduces students to indicators of reliability. As students become more confident in evaluating sources, they won't need to rely on the Checklist. This tool is used as part of teaching evaluation in first year units at Deakin University. It can be used as part of assessment or activities where students evaluate resources providing the dependability score.
The book offers a blend of theory and practice in guiding readers …
The book offers a blend of theory and practice in guiding readers to apply design thinking principles to solving some of our world’s biggest problems. At the same time, readers are encouraged to become aware of new and emerging technologies that make prototyping and applying solutions a reality.
This is a video description of a study on artificial intelligence and …
This is a video description of a study on artificial intelligence and ethics. The study is part of the requirements of the Development Communication 263 Course from the University of the Philippines Open University.
These slides provide a brief overview of some of the problematic histories …
These slides provide a brief overview of some of the problematic histories and legacies of the Dewey Decimal Classification System (and Dewey himself), particularly focusing on heterosexism and cissexism, but also sexism, racism, colonialism, and more discrimination. They critique the idea that libraries and librarians are neutral, discuss some of the creative and caring ways library workers and communities have challenged and continue to challenge and change these systems, and suggest ways we can all challenge discrimination in library classification (and other systems, policies and practices) too and why it is important that we do so.
Sharing data and code are important components of reproducible research. Data sharing …
Sharing data and code are important components of reproducible research. Data sharing in research is widely discussed in the literature; however, there are no well-established evidence-based incentives that reward data sharing, nor randomized studies that demonstrate the effectiveness of data sharing policies at increasing data sharing. A simple incentive, such as an Open Data Badge, might provide the change needed to increase data sharing in health and medical research. This study was a parallel group randomized controlled trial (protocol registration: doi:10.17605/OSF.IO/PXWZQ) with two groups, control and intervention, with 80 research articles published in BMJ Open per group, with a total of 160 research articles. The intervention group received an email offer for an Open Data Badge if they shared their data along with their final publication and the control group received an email with no offer of a badge if they shared their data with their final publication. The primary outcome was the data sharing rate. Badges did not noticeably motivate researchers who published in BMJ Open to share their data; the odds of awarding badges were nearly equal in the intervention and control groups (odds ratio = 0.9, 95% CI [0.1, 9.0]). Data sharing rates were low in both groups, with just two datasets shared in each of the intervention and control groups. The global movement towards open science has made significant gains with the development of numerous data sharing policies and tools. What remains to be established is an effective incentive that motivates researchers to take up such tools to share their data.
Differentiating open access and open educational resource can be a challenge in …
Differentiating open access and open educational resource can be a challenge in some contexts. Excellent resources such as "How Open Is It?: A Guide for Evaluating the Openness of Journals" (CC BY) https://sparcopen.org/our-work/howopenisit created by SPARC, PLOS, and OASPA greatly aid us in understanding the relative openness of journals. However, visual resources to conceptually differentiate open educational resources (OER) from resources disseminated using an open access approach do not currently exist. Until now.
This one page introductory guide differentiates OER and OA materials on the basis of purpose (teaching vs. research), method of access (analog and digital), and in terms of the relative freedoms offered by different levels of Creative Commons licenses, the most common open license. Many other open licenses, including open software licenses also exist.
Students will create an Adobe Spark to demonstrate the cell cycle and …
Students will create an Adobe Spark to demonstrate the cell cycle and mitosis. Students take pictures of hand signals to model the cell cycle and mitosis, creating a digital storybook of the stages, with short descriptions of each stage. Students also add a section about abnormal cell cycles and cancer, with a specific example named and described. Students use Adobe Spark to link the stages of the cell cycle together and animate the process, simplifying the concepts to make them easier to remember.
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.