Unrestricted Use
CC BY
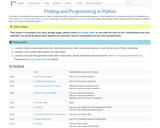
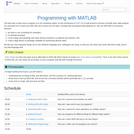
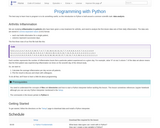
This webinar walks you through the basics of creating an OSF project, structuring it to fit your research needs, adding collaborators, and tying your favorite online tools into your project structure. OSF is a free, open source web application built by the Center for Open Science, a non-profit dedicated to improving the alignment between scientific values and scientific practices. OSF is part collaboration tool, part version control software, and part data archive. It is designed to connect to popular tools researchers already use, like Dropbox, Box, Github, and Mendeley, to streamline workflows and increase efficiency.
- Subject:
- Applied Science
- Computer Science
- Information Science
- Material Type:
- Lecture
- Provider:
- Center for Open Science
- Author:
- Center for Open Science
- Date Added:
- 08/07/2020