This resource is a video abstract of a research paper created by …
This resource is a video abstract of a research paper created by Research Square on behalf of its authors. It provides a synopsis that's easy to understand, and can be used to introduce the topics it covers to students, researchers, and the general public. The video's transcript is also provided in full, with a portion provided below for preview:
"Advances in metagenomic sequencing have allowed for the identification of countless novel bacterial taxa in environmental samples. However, due to a lack of appropriate computational tools, the plasmids contained by many of these bacteria have received far less attention. That has restricted research into the important genetic processes plasmids are responsible for, such as horizontal gene transfer and antibiotic resistance. To address this gap, researchers recently developed the Sequence Contents-Aware Plasmid Peeler (SCAPP). An open-source Python package, SCAPP builds upon a previously developed algorithm and uses biological data to assemble plasmid sequences from metagenomic samples. SCAPP was found to outperform existing metagenomic plasmid assembly tools when tested on simulated metagenomes and real human gut microbiome samples. SCAPP could also assemble novel and clinically relevant plasmid sequences in generated samples..."
The rest of the transcript, along with a link to the research itself, is available on the resource itself.
Workshop overview for the Data Carpentry Social Sciences curriculum. Data Carpentry’s aim …
Workshop overview for the Data Carpentry Social Sciences curriculum. Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools for working with data so that they can get more done in less time, and with less pain. This workshop teaches data management and analysis for social science research including best practices for data organization in spreadsheets, reproducible data cleaning with OpenRefine, and data analysis and visualization in R. This curriculum is designed to be taught over two full days of instruction. Materials for teaching data analysis and visualization in Python and extraction of information from relational databases using SQL are in development. Interested in teaching these materials? We have an onboarding video and accompanying slides available to prepare Instructors to teach these lessons. After watching this video, please contact team@carpentries.org so that we can record your status as an onboarded Instructor. Instructors who have completed onboarding will be given priority status for teaching at centrally-organized Data Carpentry Social Sciences workshops.
This book is about complexity science, data structures and algorithms, intermediate programming …
This book is about complexity science, data structures and algorithms, intermediate programming in Python, and the philosophy of science. This book focuses on discrete models, which include graphs, cellular automata, and agent-based models. They are often characterized by structure, rules and transitions rather than by equations. They tend to be more abstract than continuous models; in some cases there is no direct correspondence between the model and a physical system.
The examples and supporting code for this book are in Python. You …
The examples and supporting code for this book are in Python. You should know core Python and you should be familiar with object-oriented features, at least using objects if not defining your own. If you are not already familiar with Python, you might want to start with my other book, Think Python, which is an introduction to Python for people who have never programmed, or Mark Lutz’s Learning Python, which might be better for people with programming experience.
Think Python is an introduction to Python programming for beginners. It starts …
Think Python is an introduction to Python programming for beginners. It starts with basic concepts of programming, and is carefully designed to define all terms when they are first used and to develop each new concept in a logical progression. Larger pieces, like recursion and object-oriented programming are divided into a sequence of smaller steps and introduced over the course of several chapters.
The goal of this book is to teach you to think like …
The goal of this book is to teach you to think like a computer scientist. This way of thinking combines some of the best features of mathematics, engineering, and natural science. Like mathematicians, computer scientists use formal languages to denote ideas (specifically computations). Like engineers, they design things, assembling components into systems and evaluating tradeoffs among alternatives. Like scientists, they observe the behavior of complex systems, form hypotheses, and test predictions.
Think Stats is an introduction to Probability and Statistics for Python programmers. …
Think Stats is an introduction to Probability and Statistics for Python programmers.
*Think Stats emphasizes simple techniques you can use to explore real data sets and answer interesting questions. The book presents a case study using data from the National Institutes of Health. Readers are encouraged to work on a project with real datasets. *If you have basic skills in Python, you can use them to learn concepts in probability and statistics. Think Stats is based on a Python library for probability distributions (PMFs and CDFs). Many of the exercises use short programs to run experiments and help readers develop understanding.
As part of our NSF-funded passion-driven statistics project, we have just started …
As part of our NSF-funded passion-driven statistics project, we have just started to share more widely our “translation code” aimed at supporting folks in learning code-based software and in moving more easily between them. The pdf includes all of the basic syntax for managing, displaying and analyzing data, translated across SAS, R, Python, Stata and SPSS. http://bit.ly/PDSTranslationCodeFor more information about our full project and access to all faculty resources, email Kristin.Flaming@gmail.com
This case study is retrieved from the open book Open Data as …
This case study is retrieved from the open book Open Data as Open Educational Resources. Case studies of emerging practice.
It explores why and how open data can be used as a material with which to produce engaging challenges for students as they are introduced to programming. Through describing the process of producing the assignments, and learner responses to them, we suggest that open data is a powerful material for designing learning activities because of its qualities of ease of access and authenticity.
In two successive years, forms of open data were used to construct coursework assignments for postgraduate students at the University of Nottingham, UK. The rationale for using open data was to shift the focus towards an outward-looking approach to coding with networks, files and data structures, and to engage students in constructing applications that had real-world relevance.
Python was chosen as the programming language.
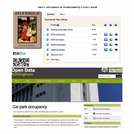
The assignment in the first year utilised e-book text files from Project Gutenberg1, and required students to build an e-reader application. In the next year, car park status data, which was made available in a regularly updated form by the city council through their open data initiative2 was used as the basis for an assignment in which students developed a city-wide car park monitoring application.
As technology continues to grow, so does access to data. Teaching students …
As technology continues to grow, so does access to data. Teaching students methods to analyze this data, identify trends, and weed out useful information is a 21st century skill that is lacking in many classrooms. This lesson will help students tackle the world of Big Data through the use of basic commands in Python which allows them to complete a one-variable data analysis determining statistical summaries and generate box plots, histograms and scatter plots.
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.