(View Complete Item Description)
With over 305,000 open educational resources cataloged on OER Commons since 2007, ISKME works to make learning and knowledge sharing more participatory, equitable, and open, in pursuit of a more just society.
Those resources don’t describe themselves, though. The metadata of every resource in OER Commons was put together by someone before it got added to our collection, and then a librarian at ISKME reviewed it for quality – and that’s a lot of work, both in and out of house!
How much work? Well, if a librarian were to spend just five minutes on each record that ever found its way into our collection, that would take 25,433 hours. That’s enough time to…
- do 123 round trips to the moon (time to finally take that leave you’ve been saving)
- get 3,178 full nights of sleep (unless you’re a cat, then it’s only 1,413)
- walk 8 times from Cape Town to Copenhagen (we’re gonna need a bigger passport)
- work full-time for over 13 years (don’t worry, that excludes 4 weeks vacation)
All of that to say, metadata takes time.
It can be a challenge to balance metadata creation with other tasks like maintaining existing records, curation work, and supporting educational partners with curation. As such, we’re always on the lookout for tools and techniques that boost our capacity without compromising quality.
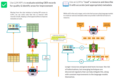
In 2023 and 2024, we’re testing out how generative AI tools like large language models can support our work in the OER landscape. This poster highlights some of the places where we’ve had successes, along with possible future applications that we think are both useful and doable.
Material Type:
Diagram/Illustration
Author:
Peter Musser